Unlocking Success with a Comprehensive Data Science Lifecycle
Stop Spinning Your Wheels in Data Science Projects

Published: Jul 15, 2025
Many new data scientists and seasoned ones jump into building models. Fancy algorithms and shiny tech catch their eyes. This shortcut derails projects, wastes time and money, and leads to weak results.
Look at the facts. Frameworks such as CRISP-DM and OSEMN give a solid base, but their broad steps leave big gaps. They are easy to understand but you may face slowdowns and half-finished answers.
Picture a simple map that takes you from the first business question to a live model and keeps the model strong.
For more tips, follow me on X @CoffeyFirst!
Are Your Data Science Projects Trapped in Ambiguity?
Beginners start projects without understanding the business goal or preparing the data. Common traps include:
- Misalignment between developed solutions and actual business questions.
- You must redo work because you ignored data prep.
- Models that fail in production due to insufficient validation or stress-testing.
Think about spending weeks on a model, then finding out it does not meet what your boss needs. It feels bad when a model crashes in real life because you skipped key steps.
A clear plan fixes this. The plan has five big stages:
- Business & Data Understanding,
- Data Prep & EDA
- Model Selection
- Tuning & Ensembling
- Validate & Ship.
For more tips, follow me on X @CoffeyFirst!
Achieve Reliable and Impactful Data Science Results with a Structured Lifecycle
Clear delineation of Business and Data Understanding:
- Guarantees alignment between business objectives, stakeholder expectations, and technical execution.
- Reduces rework and ensures models target core business requirements, maximizing business impact.
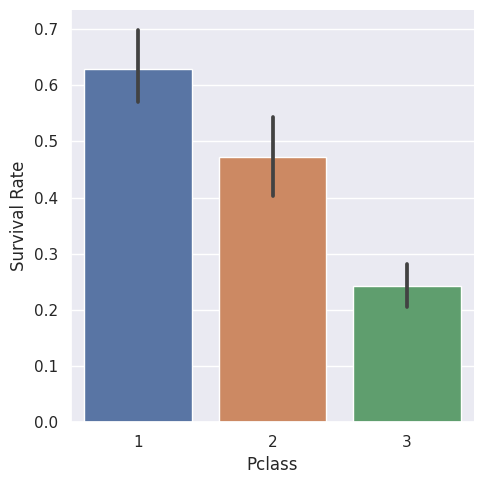
Thorough Data Preparation and Exploratory Data Analysis (EDA) using reproducible notebooks:
- Establishes early-stage data quality, consistency, and comprehensive documentation.
- Strengthens models, cuts bugs, and speeds up insight so teams decide faster.
Iterative Model Selection coupled with Robust Hyperparameter Tuning:
- Balances rapid baseline model establishment with structured and rigorous refinement processes.
- Boosts predictive power, sharpens performance, cuts wasted effort, and raises accuracy and usefulness.
Comprehensive Validation, Deployment, and Ongoing Monitoring:
- Guarantees models perform under diverse and realistic operational conditions.
- Clear results give stakeholders confidence and builds trust in the model.
For more tips, follow me on X @CoffeyFirst!
Embrace a Lifecycle That Delivers Real-World Results
Begin integrating this enhanced lifecycle framework into your processes:
Business & Data Understanding:
Business Understanding: Define the problem, success measures, and limits first.
- What exactly is the business question or problem we’re solving?
- Who are the stakeholders and end-users, and what decisions will they make from our work?
- How will success be measured (revenue lift, error reduction, user engagement, etc.)?
- What are the timeline, budget, technical or regulatory constraints?
Data Acquisition: Identify, access, and gather all relevant raw data.
- Which data sources — databases, APIs, third-party feeds, flat files, user logs — are needed?
- Is the historical coverage and granularity enough for modeling?
- How do we authenticate, extract, and store that data so it is secure?
- What metadata (schema definitions, data dictionaries) do we need to collect as well?
Data Prep & EDA:
Data Ingestion & Loading: Pull raw data in one clean, searchable format.
- What formats (CSV, JSON, Parquet, SQL tables) and partitioning schemes will you use?
- How will you version and document each data snapshot?
- Are there schema mismatches or encoding issues to resolve on ingestion?
Data Cleaning & Preprocessing: Fix quality issues to prevent misleading analyses and models.
- Which records are duplicates or erroneous?
- How will we handle missing values — delete, impute, or flag?
- What outlier-detection rules or thresholds should we apply?
- Are categorical fields consistent (e.g., “NY” vs. “New York”)?
Exploratory Data Analysis (EDA): Uncover patterns and test assumptions.
- What are the distributions of key variables?
- Which variables have strong correlation or exhibit multicollinearity?
- Are there non-linear relationships, seasonal trends, or clusters?
- Do initial hypotheses about drivers hold up?
Feature Engineering & Selection: Transform raw inputs into predictive features.
- What new features can we derive?
- How do we encode categorical variables?
- Which features add predictive power vs. noise?
- Should we apply dimensionality reduction or selection algorithms?
- Build a pipeline on the training set and apply it to both training and validation sets to stop data leaks.
Model Selection:
Model Training: Fit candidate algorithms
- What modeling families make sense (linear, tree-based, neural nets, clustering)?
- How will we split our data (hold-out set, k-fold cross-validation, time series CV)?
- Are computation and inference time within acceptable limits?
- Choose one metric to rank the models. For example: accuracy, precision-recall, MAE, ROC-AUC, or PR-AUC for unbalanced data.
Tuning & Ensembling:
Hyperparameter Tuning: Pick the best two or three models and improve them.
- Which hyperparameters will we tune, and what search strategy (grid, random, Bayesian)?
- For classification, what threshold should you use? Is specificity or recall more important?
Example from my solution to the classic Titanic ML Competition at Kaggle:
def make_xgb_cv_objective(
df_raw: pd.DataFrame, n_splits: int = 5, random_state: int = 42
):
"""
Returns an Optuna objective that runs StratifiedKFold CV on df_raw
and returns the mean accuracy across folds.
"""
def objective(trial):
hyperparams = {...}
# Stratified K-fold
skf = StratifiedKFold(
n_splits=n_splits,
shuffle=True,
random_state=random_state,
)
fold_acc = []
for tr_idx, va_idx in skf.split(df_raw, df_raw["Survived"]):
X_tr, y_tr, _, \
X_va, y_va, _ = preprocess_fold(df_raw.iloc[tr_idx],
df_raw.iloc[va_idx])
model = xgb.XGBClassifier(**hyperparams)
model.fit(
X_tr,
y_tr,
eval_set=[(X_va, y_va)],
verbose=False,
)
fold_acc.append(
accuracy_score(y_va, (model.predict_proba(X_va)[:,1] >= 0.5))
)
# All folds completed → return the final mean accuracy
return float(np.mean(fold_acc))
return objective
study_xgb = optuna.create_study(
direction="maximize",
sampler=TPESampler(seed=42),
)
study_xgb.optimize(
make_xgb_cv_objective(train),
n_trials=n_trials,
callbacks=[conv_cb],
show_progress_bar=True,
)
print("✅ XGB CV accuracy:", study_xgb.best_value)
print("✅ XGBoost best parameters:")
for k, v in study_xgb.best_params.items():
print(f" • {k}: {v}")Model Ensembling: Create an ensemble that outperforms base models.
- Aggregating outputs reduces model error and maintains generalization.
- Overcomes challenges like high variance, low accuracy, and noisy features.
- Techniques include max voting, averaging, weighted averaging.
- Types include:
- Bagging (Random Forest, Extra-Trees)
- Boosting (AdaBoost, Gradient Boosting: XGBoost, LightGBM, CatBoost)
- Stacking
Validate & Ship:
Model Evaluation & Validation: Assess performance and guard against overfitting.
- What evaluation metrics reflect business goals?
- How does performance differ between training, validation, and test sets?
- Do error patterns reveal biases or weaknesses?
- Have we stress-tested edge cases or simulated production conditions?
Interpretation & Communication: Translate findings into actionable insights.
- Top drivers of predictions (feature importances, SHAP)?
- Best visualization methods?
- Understandable trade-offs or limitations?
- Concrete recommendations or next steps?
Deployment & Monitoring: Ensure reliability and watch for drift.
- Model placement (batch, real-time API, embedded)?
- Infrastructure, versioning, CI/CD requirements?
- Logging, performance metrics, and alerts?
- Drift-detection methods triggering retraining?
Reflection & Continuous Improvement: Evolve and plan for future cycles.
- What went well vs. bottlenecks?
- Opportunities for automation or streamlining?
- More data or techniques?
- Documentation and maintainability?
Ready to change how you do data science? Start your next project with my Data Science Starter Notebook Template to put this lifecycle into action.
For more tips, follow me on X @CoffeyFirst!